Claude가 '무한 대화'를 꺼낸 진짜 이유는


한이룸
AI
2026. 5. 7.
Claude가 '무한 대화'를 꺼낸 진짜 이유는요.
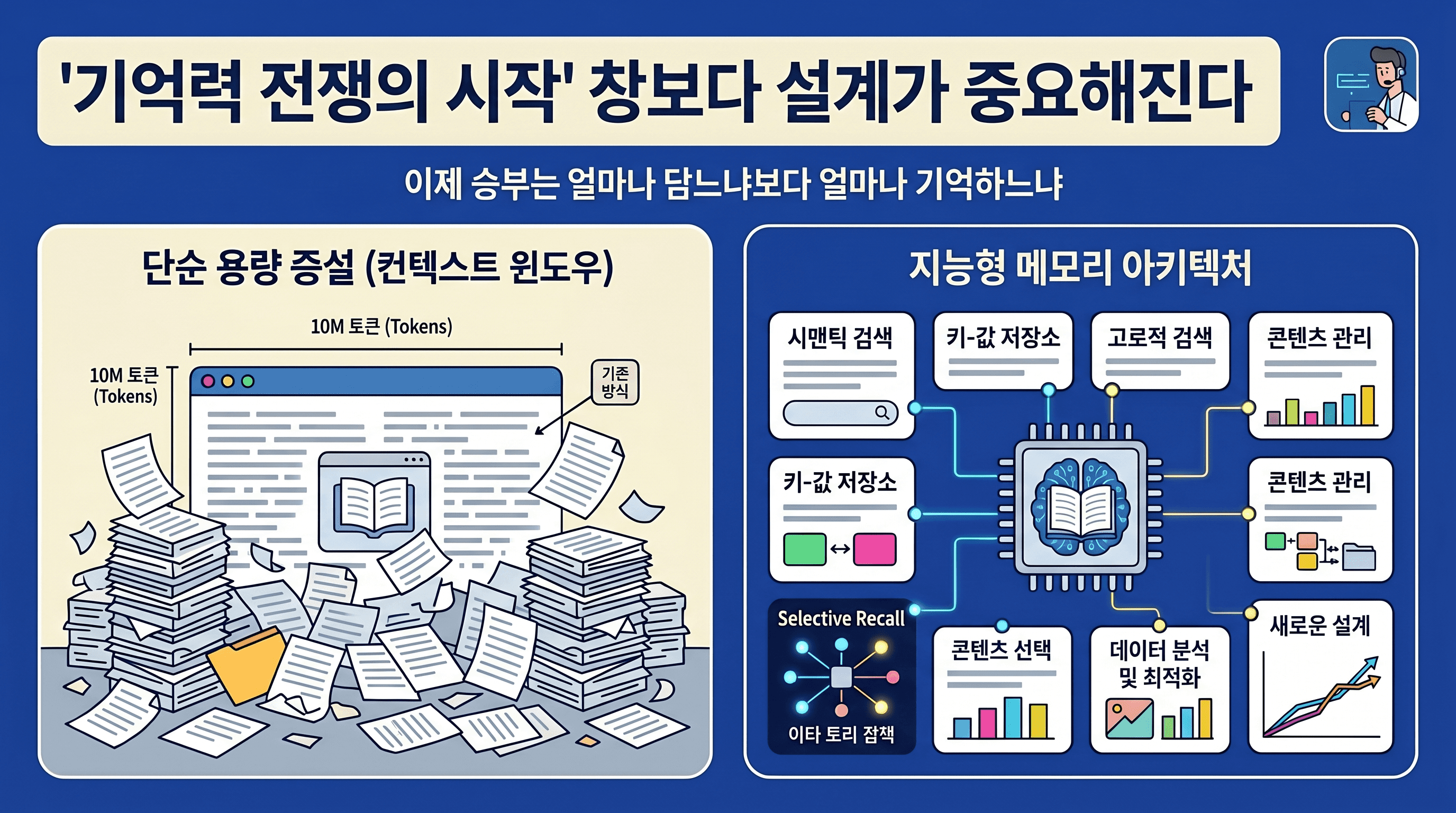
컨텍스트 창을 넓히는 게 아니라 기억을 설계하는 쪽으로 경기장을 바꾸려는 것입니다
AI를 공부하면서 느낀점은 세션, 컨텍스트가 전부라는 전부입니다.
제가 다른 강연에서도 밝혔지만, 세션을 지배하는자가 AI를 가장 잘 쓴다고 이야기 했습니다.
AI에게 긴 글을 맡겨본 사람이라면 한 번쯤 겪었을 겁니다. 대화가 길어지면 앞에서 했던 말을 까먹는 현상. "아까 말한 그 파일 기억나지?"라고 물으면 "죄송합니다, 이전 대화 내용을 참조할 수 없습니다"가 돌아옵니다. AI의 '기억력 한계'는 단순한 불편이 아니라, 복잡한 업무를 AI에게 맡기는 데 있어 가장 큰 병목이었습니다.
Anthropic이 이 문제를 정면으로 건드렸습니다.
100만 토큰, 추가 요금 없이

2026년 3월 13일, Anthropic은 Claude Opus 4.6과 Sonnet 4.6에 100만 토큰 컨텍스트 윈도우를 정식 개방했습니다. 100만 토큰은 대략 75만 단어, 한국어 기준으로 A4 용지 1,500장 분량입니다. 소설 열다섯 권을 통째로 넣고 "3권 중반에 나온 그 복선, 결말에서 회수됐나?"라고 물을 수 있는 크기입니다.
더 눈에 띄는 건 가격 정책의 변화입니다. 이전에는 20만 토큰을 넘기면 할증이 붙었습니다. Opus 4.6 기준 입력 토큰 가격이 $5에서 $10으로 두 배가 됐고, Sonnet도 마찬가지였습니다. 이제 그 할증이 사라졌습니다. 100만 토큰을 넣든 10만 토큰을 넣든 같은 단가입니다.
경쟁 구도를 보면 이유가 보입니다. Google의 Gemini 3.1 Pro는 이미 200만 토큰을 지원합니다. 순수한 창 크기만 놓으면 Claude의 다섯 배입니다. Anthropic 입장에서 100만 토큰에 할증까지 붙이면 승부가 안 됩니다. 가격 장벽을 없애는 건 경쟁 전략이기도 합니다.
진짜 흥미로운 건 '압축' 쪽입니다
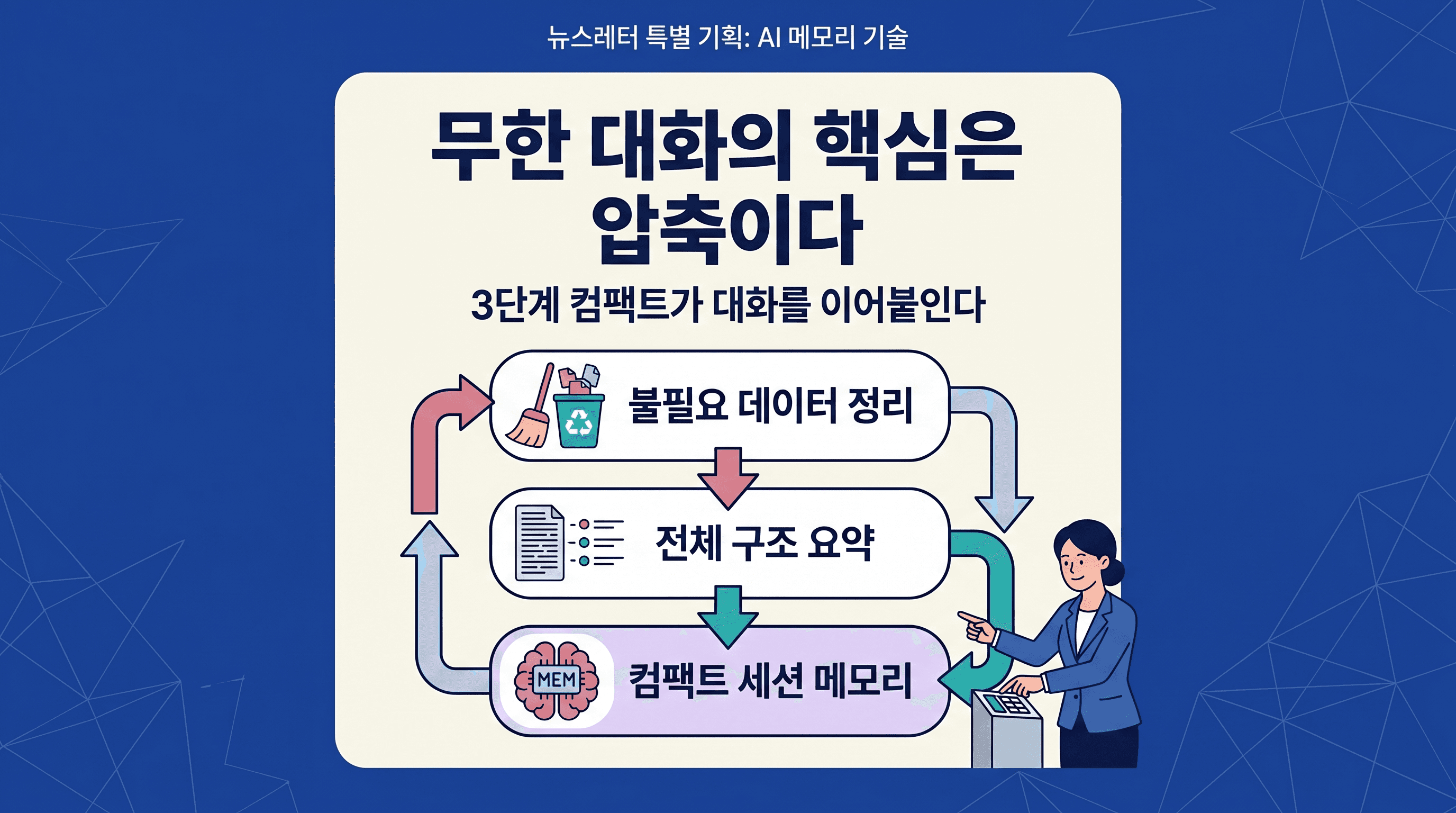
하지만 Anthropic이 진짜 공을 들인 건 컨텍스트 창을 넓히는 것보다, 한정된 창 안에서 대화를 끊기지 않게 만드는 기술입니다. Claude Code에는 이미 '무한 대화'를 가능하게 하는 3단계 압축 시스템이 돌아가고 있습니다.
1단계: 마이크로컴팩트 (비용 0원). 사용자가 60분 정도 자리를 비우면, 오래된 파일 읽기 결과, 셸 명령어 출력, 검색 결과 같은 '다시 만들 수 있는' 데이터를 자동으로 지웁니다. 최근 5개만 남기고 나머지는 버립니다. AI 모델을 호출하지 않으므로 비용이 들지 않습니다.
2단계: 풀 컴팩트 (비싸지만 정확함). 마이크로컴팩트로 부족하면 AI 모델이 직접 대화 전체를 9개 섹션으로 요약합니다. 사용자가 한 말은 원문 그대로 보존하고, 기술적 결정사항, 발견한 버그, 다음 할 일까지 구조화합니다. 요약 후에는 최근 작업한 파일 5개(최대 5만 토큰)와 활성 스킬(2만 5천 토큰)을 다시 불러옵니다. 압축했다가 필요한 것만 복원하는, 일종의 '선택적 기억 재생'입니다.
3단계: 세션 메모리 컴팩트 (가장 저렴함). 백그라운드에서 지속적으로 대화 내용을 구조화된 마크다운 노트로 추출합니다. 현재 상태, 작업 사양, 파일 목록, 에러 기록 등 9개 카테고리로 나누고, 각각 2,000토큰 이내로 압축합니다. 전체 합쳐 12,000토큰. 이 노트가 이미 있으면 모델 호출 없이 노트만으로 대화를 이어갑니다.
실제 작동 기준을 보면, Claude Code의 자동 압축은 대략 16만 7천 토큰 부근에서 발동합니다. 20만 토큰 컨텍스트에서 출력용 버퍼와 안전 마진을 빼면 그 정도가 됩니다. 압축이 3회 연속 실패하면 서킷 브레이커가 작동해 더 이상 시도하지 않습니다. Anthropic 텔레메트리에 따르면, 이 안전장치가 없던 시절에는 50회 이상 압축 실패가 발생한 세션이 1,279개 있었고, 하루에 약 25만 건의 API 호출이 낭비되고 있었습니다.
'꿈꾸는' AI: Auto Dream

여기에 한 가지가 더 있습니다. Anthropic은 'Auto Dream'이라는 기능도 도입했습니다. 세션과 세션 사이에 Claude가 자기 메모리 파일을 스스로 정리하는 기능입니다. 오래된 메모를 삭제하고, 중복을 합치고, 모순되는 내용을 해결합니다. 사람으로 치면 잠자는 동안 뇌가 기억을 정리하는 과정과 비슷합니다. 이렇게 하면 다음 세션 시작 시 불필요한 토큰 소비가 줄어듭니다.
조심해서 봐야 할 지점

첫째, '무한'은 마케팅 용어입니다. 실제로는 요약이 반복될수록 정보가 손실됩니다. Anthropic도 이걸 알기에 압축 후 파일 5개를 다시 읽어오는 '복원' 단계를 넣었지만, 12시간 전에 논의한 미묘한 맥락이 100% 살아남는다는 보장은 없습니다.
둘째, 풀 컴팩트는 대화 전체를 다시 처리하므로 프롬프트 캐시가 무효화됩니다. 모든 토큰이 캐시 미스가 되어 그 한 번의 호출이 비쌉니다. 평소에는 캐시 적중률 98%를 유지하다가 압축 순간에 0%로 떨어지는 구조입니다.
셋째, 창 크기 경쟁에서 Claude는 뒤쳐져 있습니다. Gemini 3.1 Pro의 200만 토큰에 비해 Claude는 100만 토큰입니다. 다만 맥락 창이 크다고 반드시 좋은 건 아닙니다. 연구들에 따르면 컨텍스트 창 중간에 넣은 정보는 양 끝에 비해 검색 정확도가 떨어지는 'Lost in the Middle' 현상이 있고, 이 문제는 창이 클수록 심해집니다.
넷째, 이 모든 것은 주로 Claude Code, 즉 개발자 도구에서 돌아가는 기능입니다. 일반 채팅에서는 대화가 길어지면 앞부분을 요약하는 정도이고, 3단계 압축 시스템 같은 정교한 구조는 아직 코딩 환경에 집중되어 있습니다.
왜 이게 중요할까요
'컨텍스트'라는 단어가 기술 용어처럼 들리지만, 본질은 간단합니다. AI가 얼마나 많은 걸 기억하고 일할 수 있느냐의 문제입니다. 이전에는 AI에게 복잡한 업무를 시키려면 사람이 직접 대화를 쪼개고, 앞에서 한 말을 다시 붙여넣고, 맥락을 수동으로 관리해야 했습니다. 그건 '도구'가 아니라 '까다로운 신입'에 가까운 경험이었습니다.
Anthropic의 접근이 흥미로운 건, 단순히 창을 넓히는 대신 '기억을 설계하는' 쪽을 택했다는 점입니다. Google이 "우리 창이 더 크다"로 승부하는 동안, Anthropic은 "같은 크기에서 더 오래, 더 정확하게 기억한다"는 방향을 잡았습니다. 사람의 기억도 모든 걸 저장하는 게 아니라 중요한 걸 남기고 나머지를 버리는 방식으로 작동하니까, 어쩌면 이쪽이 더 현실적인 길일 수 있습니다.
AI 기억력 전쟁은 이제 "얼마나 많이 넣느냐"에서 "얼마나 잘 기억하느냐"로 넘어가고 있습니다. 이 경기장에서는 아직 누가 이길지 모릅니다.